画像ベースのテキスト認識
内容
1. 概要
2. キャラクターイメージコレクション
3. キャラクターキャプチャウィザード
1.概要
IBTR(Image Based Text Recognition)
は、HeartCore Robo Desktop 3.0で導入された新機能で、保存された文字の集合に基づいて画面上のテキストとその座標を認識することができます。
IBTR機能は、次の3つのコンポーネントで構成されています。
- スクリプト言語仕様で説明されている「text」比較メソッド。
- キャラクターイメージコレクション、
- キャラクターキャプチャーウィザード
この機能は、2.xリリースのアドオンとして提供されるImage Based Text Recognition プラグインとパラメータ互換ではありません。プラグインベースのスクリプトコードを変換するには、tolerance
パラメータをpassrateに置き換えます。
passrate = 100 *(1 - 公差/ 85)
合格率に換算されたサンプル公差値の近似表:
耐性
|
合格率
|
0
|
100
|
10
|
88
|
20
|
76
|
30
|
65
|
40
|
53
|
50
|
41
|
60
|
29
|
70
|
18
|
85
|
0
|
2.キャラクターイメージコレクション
キャラクターイメージコレクションは、
これらの規則を満たしている文字画像を含むディレクトリです。
- コレクションディレクトリには、「 uNNNN」という名前のフォルダ(「文字フォルダ」)が含まれています。「NNNN」は、4桁の大文字の16進UTF-8文字コードです。たとえば、 'M'文字はUTF-8コードが77(0x4D)なので 'u004D'というフォルダで表す必要があります。
- それぞれの文字フォルダには、Javaでサポートされているロスレス形式の文字イメージが1つ以上含まれています(PNGが優先され、BMPもサポートされていますが、大きくなる傾向があります)。イメージファイル名は関係ありませんが、ファイル拡張子はイメージフォーマットに関して正しいものでなければなりません。例えば、PNG画像は ".png"拡張子を持つファイルに保存する必要があります。
'a'文字と 'o'文字の2つの変種を含む文字集合の例は次のようになります:
C:\MyAutomation\charset
- u0061\
-
a1.png
-
a2.png
- u006F\
-
o.png
コレクションの推奨事項:
- 内部アルゴリズムは、コレクションイメージからテキスト行とスペースサイズの高さを導出するので、異なるフォントタイプおよび/またはサイズの文字イメージを単一のコレクションに混ぜてはなりません。異なるフォントと背景色の文字画像を混在させることは、文字のフォントタイプとサイズが同じであればOKです。
ロボットはキャラクターキャプチャウィザードを使用してキャラクタイメージコレクションの作成とメンテナンスをサポートしていますが、そのようなコレクションは手作業または第三者のイメージエディタで作成および編集できます。これは、IBTRによって内部的に使用される画像検索アルゴリズムのいくつかの機能を利用するのに便利です。例えば、任意の背景で動作する文字集合を作成するには、画像エディタで文字画像を編集し、背景を透明または半透明にすることができます。
3.キャラクターキャプチャウィザード
キャラクターキャプチャウィザードは
、ビューを作成し、文字画像のコレクションを維持することを可能にするフロントエンドGUIウインドウです。ウィザードは、[ ツール ] - > [文字キャプチャ ]メニュー項目から開始できます。
最初のウィザード画面の、画像コレクション の選択は、使用する文字画像ディレクトリの選択を扱います。
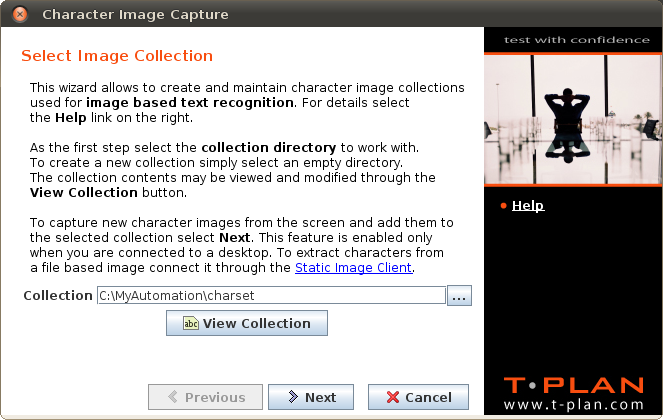
[コレクションの表示]ボタンは、コレクションフィールドに既存のディレクトリが含まれている場合にのみ有効です。これは、文字イメージのツリーと、コレクションによってカバーされる文字を示す UTF-8 文字セットテーブルから成るコレクションの詳細を含む新しいウィンドウを開きます。ビューアでは、キャラクタイメージの編集や削除などの基本的なメンテナンス作業を可能にします。
選択したコレクションに新しい文字イメージを追加するには、[ 次へ]をクリックして[テキストの選択 ]
画面に進みます。このボタンは、ロボットがデスクトップに接続されている場合にのみ有効になります。ファイルに保存されている静止画像から文字を抽出する必要がある場合は、ログインウィンドウを使用して静止画像クライアントを介して画像を読み込みます。
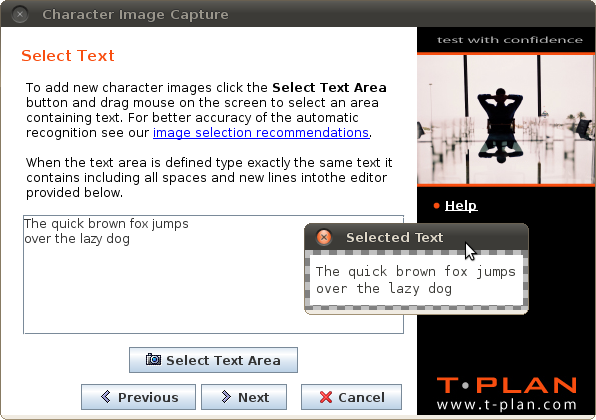
新しい文字を画面から抽出するには、次の手順を実行します。
- テキスト領域の選択
ボタンをクリックします。リモートデスクトップのコピーを含む新しいウィンドウが開きます。次に、画像内でマウスをドラッグして、テキストを含む領域をマークします。テキスト選択のヒントについては、以下の推奨事項の章を参照してください。完了したら、選択項目の横にある緑色のチェックマークをクリックするか
、ツールバーの保存&クローズボタンをクリックします。
- 画像のテキストをボタンの上にあるエディタに入力します。すべてのスペースと行に表示されているとおりに正確に入力してください。
イメージを選択し、テキストが次へを押すと、最後の「文字イメージの確認」画面が表示されます。
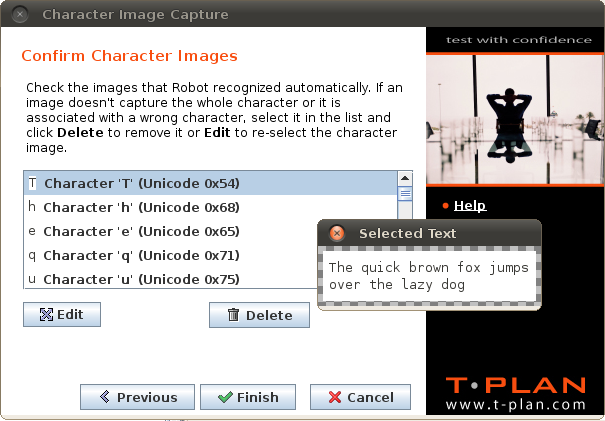
この画面には、指定されたテキストに含まれる文字のリストが表示されます。ロボットが画像内のピクセルレベルの個々の文字を認識すると、リストには候補の文字画像が表示されます。文字を削除または変更するには、[削除]
ボタンと[ 編集]ボタンを使用します。重複した画像を扱う必要はないことに注意してください。文字イメージがすでに存在し、それが新しく抽出されたイメージイメージと同じ場合、それは自動的にスキップされます。
いくつかのシナリオでは、ロボットは個々の文字のテキスト領域イメージを解析できないことがあります。これは、例えば、選択されたテキスト領域が推奨基準を満たさない場合に起こり得ます。認識できない文字がリストに表示され、このような赤のN / Aアイコンが表示されます。

この現象は、文字コレクションを使用して文字を検索できないことを意味するものではありません。単にウィザードが文字イメージを示唆できなかったことを示しています。これを修正するには、単にリスト内の文字を選択し、編集をクリックしてテキスト領域にその画像を手動で定義します。
テキスト領域の選択に関する推奨事項
これらのヒントは、手動で固定する必要がある認識できない文字(N / A)の数を最小限に抑えるために、画面上のテキスト領域を選択する方法を示唆しています。
- 選択領域の最初のピクセル(左上隅)は、背景色でなければなりません。
- この領域には、単一のフォントタイプのテキスト、サイズおよび色が単色の背景に表示されます(たとえば、白い背景に黒いテキストのブロックなど)。テキストがこれらの要件を満たしていない場合は、この基準を満たすより小さい部分で(単語および/または行で)処理します。
- この領域には、テキストメッセージ、ボタンラベル、メニュー項目など、単一のグラフィックコンポーネントに表示される1つの連続したテキストブロックが含まれている必要があります。たとえば、2つ以上のボタンを含む領域は、テキストが水平軸に沿って異なる位置に配置される可能性があるため、選択しないでください。
- ロボットが背景色の空間を探して文字を分離するので、文字が垂直軸または水平軸に沿って重なっているフォントは解析できず、手動で抽出する必要があります。このような文字イメージに別の文字の一部が含まれている場合、これらはGimpなどのサードパーティのイメージエディタで削除する必要があり、文字検索アルゴリズムをスキップするには、その影響を透過的にする必要があります。