MySQL Cluster Cases
Outline
Electron Manufacture
| Version | MySQL Cluster 7.2 |
|---|---|
| Introduced to | Internal system of Quality Assurance department - for mechanical parts searching |
| Purpose | For high speed retrieval using the in-memory database which is one of the main feature of MySQL Cluster. |
| Background |
They needed to speed up their fuzzy search as there were thousands of product parts in the system. Due to the current system constructing MySQL, they wanted to reduce the cost for DP/APL. |
| Method | - Existing table structure is migrated as is. - Data structure is changed to support fuzzy search - Distribution Awareness (user-defined partitioning) is performed by DataNode distribution.
|
| Effects |
It now takes only a few seconds to retrieve search results, which used to take more than an hour. |
Architecture
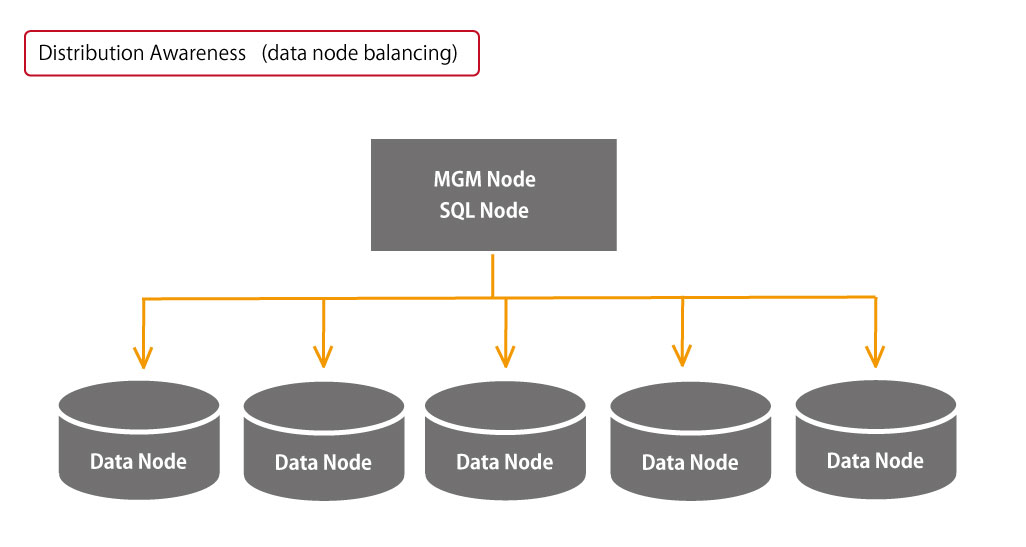
The system called Distribution Awareness, which distributes data nodes, is applied. In this case, data nodes are divided into five. The search speed has been dramatically increased by implementing the optimized data node distribution.
For instance, it is now possible to store data by specifying like "Input all data related to column 115 into the same place".
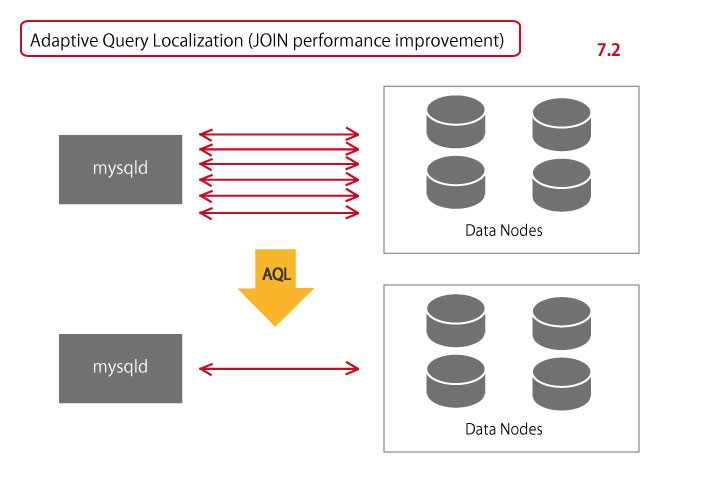
One of the main reasons to decide to introduce MySQL Cluster was JOIN performance had been dramatically improved since MySQL Cluster 7.2. It used to require data fetching for every row through network, which was a big concern about performance. Since 7.2, however, it has become possible to execute JOIN inside a data node and network communications have drastically decreased.